Abstract
Drawing on two accounts of information literacy, one from American students and another from teenaged Macedonian fake news makers, I argue that developing an information literacy reflective of the monetized and hierarchical nature of networks is paramount to writing and research. Focusing on the relationship between technological discourse—what is said about technology—and literacy—what people do with technology, I argue that recognizing the influence of corporations and differences between print and digital media are paramount for the development of information literacy.
Keywords: digital networks, Googlization, information literacy, digital literacy, technological discourse, digital democracy
Contents
Scene One: Students in the U.S.
Scene Two: Teenagers in Macedonia
Conclusion: Developing Information Literacy for a Corporatized Network
Introduction
Jon Stewart was booked to appear on CNN’s Crossfire on October 15, 2004 to promote his recently-released book, America. Leading up to Stewart’s segment, co-hosts Paul Begala (sitting on the left, punditing for the left) and Tucker Carlson (sitting on the right, punditing for the right) both referred to Stewart as “the most trusted man in fake news.” Rather than promote his book, Stewart used the opportunity to confront the co-hosts, accusing them of failing to promote informed public discourse through journalism, creating instead a “theater” of “partisan hackery.” As Stewart said during the segment, “I made a special effort to come on the show today, because I have privately, amongst my friends and also in occasional newspapers and television shows, mentioned this show as being bad,” because “it’s hurting America” (Felker). In defense, Carlson confronted Stewart about a recent Daily Show interview with then-presidential candidate John Kerry and accused Stewart of failing to ask Kerry a question of substance: “You got the chance to interview the guy. Why not ask him a real question, instead of just suck up to him?” Stewart responded, “You’re on CNN. The show that leads into me is puppets making crank phone calls.” The audience of the episode outpaced the normal viewership by about 200,000 and increased after a transcript was published to CNN’s website and clips of the segment were posted to YouTube (“Crossfire (TV Series)”).
My purpose in discussing this moment in television history is to emphasize the importance of understanding the networks that enable the production and delivery of fake news. Although Stewart’s appearance involved networks of a different kind than those used to circulate the fake news stories that are the focus of this special issue, his appearance indicates that knowledge of networks is vital for assessing information in its appropriate context (Gosnick, Braunstein, and Tobery). The importance of understanding the role of the network is reflected in the recently released Association of College & Research Libraries’ (ACRL) “Framework for Information Literacy for Higher Education,” a document that has prompted a growing body of scholarship within writing studies keyed to helping students further develop information literacy (D’Angelo et al.). Key to the ACRL’s framework is the understanding of digital networks as a diverse “information ecosystem” within which students have a participatory role. The framework notes that
the rapidly changing higher education environment, along with the dynamic and often uncertain information ecosystem in which all of us work and live, require[s] new attention to be focused on foundational ideas about that ecosystem. Students have a greater role and responsibility in creating new knowledge, in understanding the contours and the changing dynamics of the world of information, and in using information, data, and scholarship ethically.
The ecosystem metaphor proves useful here not only to emphasize the variety of information that circulates through networks but also to account for the interdependencies between humans—subjects, researchers, sponsors—and non-human-entities—data, information, algorithms, systems—within research networks. While the ACRL emphasizes how humans understand and use information, Kathleen Blake Yancey emphasizes how researchers contribute to the information ecosystem. She observes that research is conducted and reported within a research ecology of sites, activities, and texts that “have always existed, but are now, with the affordances of the Internet, more visible, inclusive, and interactive” (“Creating” 83). A Google search, for example, might yield published research typically housed in a library’s stacks or hosted in a library’s database, alongside raw data and early findings that researchers have made available in “multiple venues ranging from scholarly websites to personal or professional blogs, personally hosted websites, and other social media outlets” (Yancey 83). Thus, beyond the use of networks, Yancey notes that research is published in a variety of outlets depending on the goals and incentives of sharing that research, be it for professional advancement or social capital. Further, by way of search engine algorithms like Google’s PageRank, credible and valuable information and “incredible—facts, data, personal narrative, rumors, information, and misinformation” are both likely to float to the top of a Google search result because of a shared link, key term, domain name, or platform (Yancey 90).
Networked information is dynamic and uncertain to be sure, but too often, these realities are not reflected in what students are taught about discerning between credible and incredible information. At my own institutional home, materials created for student-researchers by the library flatten much of this complexity by discussing only two criteria for source evaluation: whether peer reviewed or not, whether primary or secondary. Given the intricacies of networks, these commonly used criteria and the model of research that undergirds them are not sufficient to help students develop effective information literacies or research practices. As the ACRL framework suggests, attention to the varied nature of networked information is integral to preparing students to assume ethical and participatory roles in the information ecosystem.
In what follows, I provide two accounts of two very different kinds of researchers and writers, each representative of a specific technological discourse about the nature and function of digital networks. In the first account, I discuss the experiences of novice researchers—primarily college students—in the process of developing necessary literacies to discern the credibility of information found online. In the second account, I discuss the Macedonian teenagers who turned the sharing of misinformation into a cottage industry during the 2016 presidential election. Like the account of fake news that opened this discussion, these 21st century fake news reporters offer two important insights about the nature of networks that students access when conducting their own research. First, these fake news makers’ efforts emphasize the importance of developing a network-specific information literacy—one that emphasizes the diverse constellation “of media, technologies, rhetorical venues, discourse genres, and distribution mechanisms” employed to share information (Porter 208). Second, as part of a network-specific information literacy, the practices these fake news makers employed to profit from misinformation emphasize the need to develop a more complete narrative about the nature of the networked information. Narratives about technology or “technological discourse” foster the ways in which technologies are received and understood in the “cultural sphere” (McCorkle 25).
As I will show, technological discourse about networks in research-focused writing classrooms has too often emphasized sameness between networked information and print sources, thus underpreparing students to evaluate networked information. While emphasizing similarities between print and digital sources encourages students to develop a modular and coherent set of strategies for evaluating sources, it has also had the effect of creating misunderstanding among students about the relationships among networks, researchers, and information. Inversely, because the community of teenaged fake news makers in Veles, Macedonia developed a network-specific information literacy undergirded by a technological discourse that reflected the realities of networks, they were able to enact skillfully a kind of information literacy that made them effective researchers and “rhetorically smart distributors as much as producers of discourse” (Porter 215). By developing an account of the Velesian teenagers’ information literacies alongside the experiences of novice researchers, my goal is to highlight the importance of developing and sharing with students a technological discourse that provides a more complete account of how information is structured, promoted, and commodified within networks. As a start to developing technological discourse for students that is reflective of the way information circulates within networks, I conclude with a pedagogical recommendation for helping students develop a network-specific information literacy.
Scene One: Students in the U.S.
On November 22, 2016, the Stanford History Education Group (SHEG) released an executive summary of its 18-month study of students’ ability to judge the credibility of information published online, “Evaluating Information: The Cornerstone of Civic Online Reasoning.” The report was timely and resonant, released at the beginning of a cascade of reports on the effects and origins of the fake news stories that circulated virally during the 2016 presidential election.1
Although SHEG’s study did not address profit-driven fake news explicitly (or intentionally deceptive information exclusively), their report shows that evaluating information online involves more than discerning the real from fake. In the current moment, readers also must be able to tell the difference between sponsored content and news as well as between advocacy and research. The report detailed findings from an 18-month study of 7804 responses from middle school, high school, and college students across 12 states.
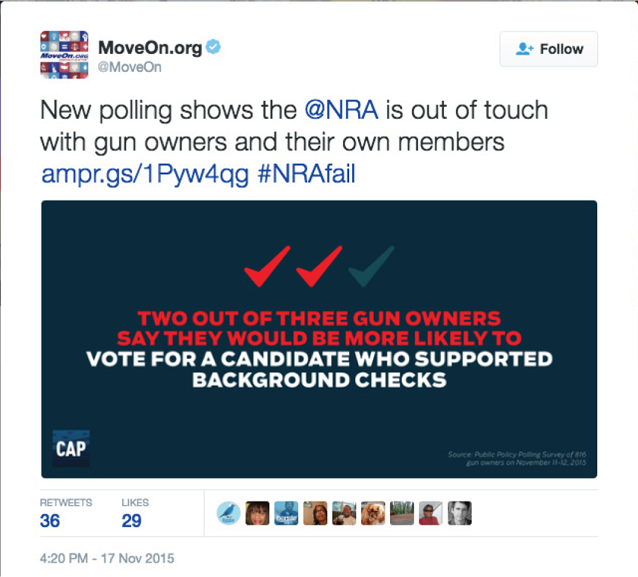
Figure 1. Tweet used in the SHEG study to evaluate students’ ability to identify the difference between advocacy and research.
The executive summary focuses on three tasks completed by three different student populations. First, middle school students were asked to discern the difference between an advertisement; a native advertisement (an ad matching the platform where it appears, for example, Melanie Deziel’s ad for Orange is the New Black available here: https://nyti.ms/2kXf4AT); and an article on a homepage. High school students were asked to evaluate a claim made through an image shared on Imgur about the Fukushima fallout (see fig. 2), and finally, college students were asked to consider the credibility and usefulness of polling data about the NRA shared by MoveOn.org through Twitter (see fig. 1). Through this study, the SHEG concluded that students’ ability to evaluate content online is “bleak” because although students “may be able to flit between Facebook and Twitter while simultaneously uploading a selfie to Instagram and texting a friend,” they are “easily duped” by “information that flows through social media channels” (4).
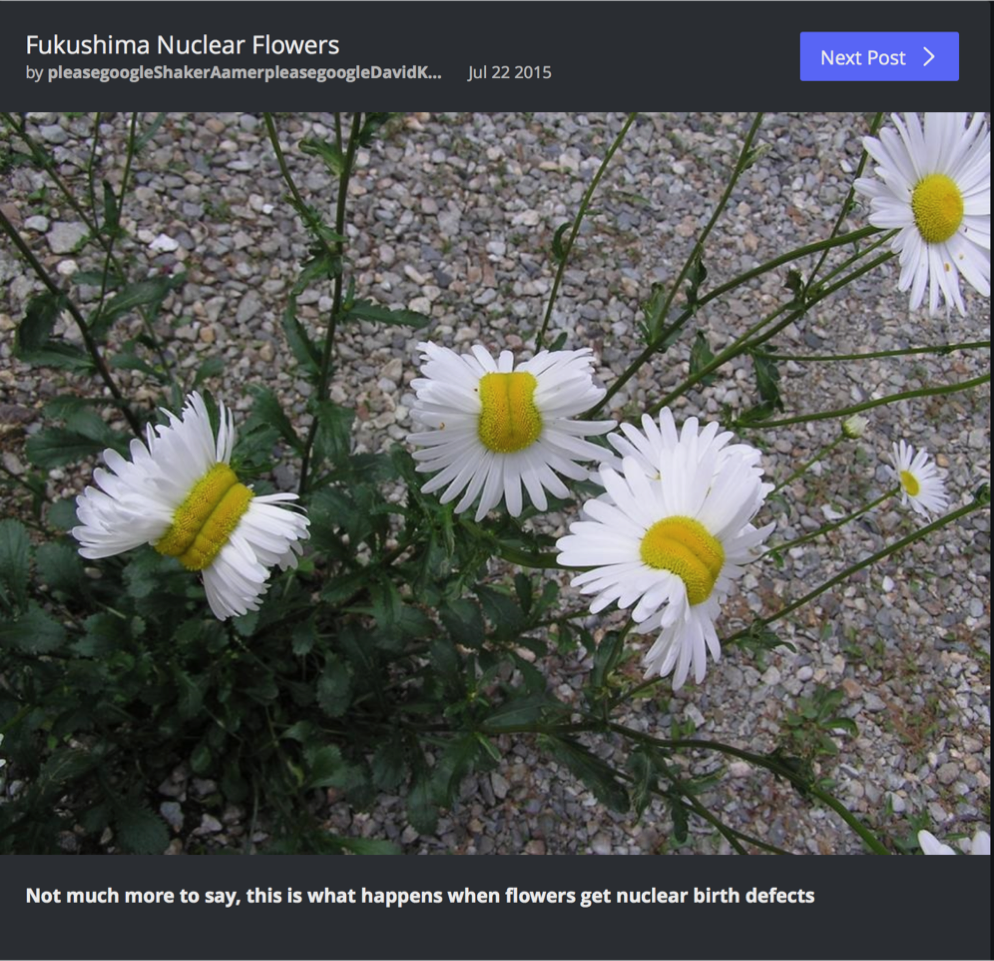
Figure 2: Fukushima flower Imgur post used by the SHEG study to evaluate students’ ability to evaluate images.
Although the Stanford group makes some troubled assumptions about students as digital natives by assuming that students born in the digital age are naturally savvy users of technology, their distinction between use and critique is valid. Even though a student might have developed the technological skills needed to write in the digital age (what Stuart Selber refers to as a “functional literacy”), evaluating information online involves a different set of literacies that the SHEG’s informants have not yet developed (Selber 44). To start, given the multimodal nature of the texts that circulate online, students needed a more fully-developed visual literacy to read the images like the Fukushima flower post as a symbol: neither necessarily a realistic representation of reality nor dependent on the caption for its meaning (Kress and van Leeuwen 21). In addition to visual literacy, the Stanford Group’s study also shows that students had not yet fully developed an information literacy needed to evaluate sources accurately. Further, the information literacy that some of the informants had developed was not helpful, leading some of the study’s informants to “accept a .org top-level domain name” as credible despite its one-sidedness (Wineburg and McGrew). Reporting a similar finding, Karen Gosnick, Laura Braunstein, and Cynthia Tobery found in their study of novice researchers’ literacy practices that while their study’s informants were “adept at finding information,” they struggled to evaluate that information for credibility (169). Like the informants in the Stanford study, Gosnick, Braunstein, and Tobery found that there is a tendency among novice researchers to choose sources that seem credible based on information like the ending of the URL.
First, students from several different classes cited a page from Stanford University’s archive of the papers of Martin Luther King, Jr. The item turns out to be a class paper on the Great Awakening that King wrote as a seminarian. When questioned regarding this choice during our debriefing discussion, students replied that they thought any “.edu” website was authoritative, since, to them, it appeared to have been written by a professor. They were unfamiliar with the concept of digital archives and other materials being hosted by an academic institution—or that “.edu” sites could just as likely be authored by students like themselves. (169)
Although their unfamiliarity with digital archives and realities of hosting presents its own set of problems, the tendency of Gosnick, Braunstein, and Tobery to attribute credibility to domain names is resonant in a moment where there is a history of recirculating information found on sites whose names are intentionally deceptive: like ABCnews.com.co and beforeitsnews.com.
Discussing another source commonly used among their informants, Gosnick, Braunstein, and Tobery describe the “persistent (yearly) appearance of a page from Theopedia,” an encyclopedia run by evangelical Christians for evangelical Christians to reaffirm the Christian faith. The researchers found that students “had not investigated this information” in part because Theopedia looks like Wikipedia; both use the MediaWiki web application to run their sites (170). Additionally, many of the study’s informants did not know that sites often include an “About” page that helps researchers “place this information in its proper context—to understand how it was produced, by whom, and for what purpose” (171). As Elizabeth Flietz has recently discussed in the Digital Rhetoric Collaborative’s post-election Blog Carnival, novice researchers tend to only “read vertically on a site, reading it as if it were a printed text” rather than reading information found online as networked.
This gap between the nature of information and the ways in which students perceive information is created—in part—by the ways that media are discussed in relation to research. Put differently, the information literacies that students cultivate are reflective of the discourse used to describe the technologies traditionally used to share and access information. As Ben McCorkle argues, two different kinds of technological discourses emerge alongside new technologies, each forwarding a different narrative about the relationships between old and new media. McCorkle writes
Generally speaking, contemporary rhetoric utilizes two logics or strategies in its efforts to incorporate digital writing more easily into our environment. One strategy involves creating connections between nascent and long-established forms of communication in order to foster a sense of familiarity and naturalness in the new class of technology— in short, a strategy of immediacy. The other, hypermediacy, works by emphasizing the benefits or affordances of the new technology over older ones, creating a sense of added value that makes a society more prone to accept it (for example, digital writing extends our ability to communicate more effectively than earlier types of writing because of the inherent efficiency of cutting and pasting preexisting text, or similar claims). (153)
Although McCorkle’s discussion of technological discourse is focused on the rhetorical tradition, his identification of two discursive strategies of technological inclusion, a strategy of immediacy and a strategy of hypermediacy, proves useful for naming different approaches to fostering students’ information literacies. The practices that Gosnick, Braunstein, and Tobery’s informants employed—like only reading vertically—are reflective of discourse that emphasizes what print and digital media have in common: a strategy of immediacy. In contrast and exemplifying a strategy of hypermediacy, recent efforts like Mike Caulfield’s self-published textbook, Web Literacy for Student Fact Checkers, discusses source evaluation with an emphasis on the differences between media: a strategy of hypermediacy. However, hypermedia strategies like those in Caulfield’s book have been slow to supplant traditional approaches that rely on strategies of immediacy like, for example, the list of guidelines for evaluating sources published by Columbia University’s Millstein Undergraduate Library (see fig. 3).2
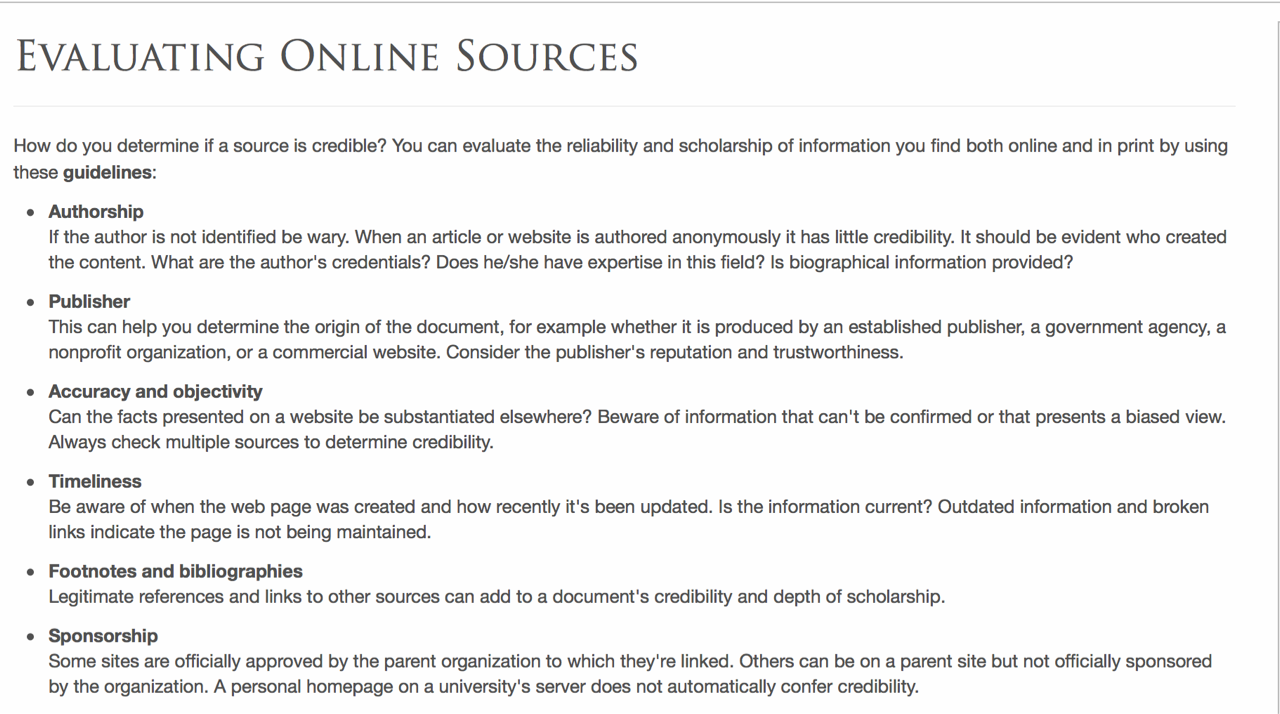 Figure 3: The Millstone Library’s published guidelines for evaluating online sources.
Figure 3: The Millstone Library’s published guidelines for evaluating online sources.
Like many others of its kind, the Millstone Library’s guidelines for evaluating sources includes both print and digital sources, and in the case of three criteria—accuracy and objectivity, timeliness, and sponsorship—there is a specific focus on digital sources. Further, their guidelines for accuracy and objectivity resemble Michael Caulfield’s recommendations to “check previous work,” “go upstream to the source,” and “read laterally.” Despite the strengths of the Millstein Library’s guidelines, the list reads like a revision: originally developed for print sources and adapted later to include sources found online. The guidelines for sponsorship, for instance, are not reflective of the sometimes-complicated relationships between content producers and hosting sites. In the case of sponsored content, advertorial articles are hosted by one organization and sponsored by another, or in the case of sharecropped articles, non-staffed writers’ posts are reposted to well-known outlets like HuffPost with little editorial oversight.
More telling of the Millstone Library’s emphasis on what print and digital media have in common are the guidelines for discerning the authorship of articles because they are reflective of a print-centric view of authorship. Beyond guidelines referring to the anonymity and credentialing of authors, the Millstein Library’s guidelines do not reflect how authorship has been transformed by cloud-based office suites like Google Drive and database-driven content management systems like wikis. In his landmark work on hypertext, George Landow argues that maintaining a focus on the author is a limited approach, reflective of book-centric understandings of authorship that obscure the collaborative and intertextual nature of research (40). As opposed to the book-centric emphasis on individual texts created and owned by individual authors, hypertext emphasizes interdependent relationships among writers and texts (Landow 137). Thus, by discussing authorship in terms of naming and credentialing without attention to models of authorship like Wikipedia’s—anonymous, edited, and version-based collaboration—the Millstein Library’s guidelines and others like it that do not attend to the differences among media do not adequately prepare students to understand and ethically use source materials they find through research.
In the next section of this discussion, I focus on the second strategy of technological discourse that emphasizes the benefits of—and thus the differences between—print and digital media. However, as Kathleen Blake Yancey notes in her 2004 CCCC address, discourse about what a technology can do is multifaceted, depending on who produces that discourse and for what reason. In her discussion of the changing nature of technology through use or the “deicity of technology,” she notes that as new technologies take hold and new literacies emerge, people find new uses for those technologies that “may be at odds with its design” (“Made” 319). The Macedonian fake news moguls discussed in the next section found ways to profit personally from a range of new uses for a constellation of technologies. Like Jon Stewart, the pre-eminent fake news reporter, this new generation of fake news reporters highlight the influence of networks on discourse, particularly the ways in which companies like Google and Facebook have undermined the initial promise of the internet as a means of empowering ordinary citizens to compete with media companies for political influence.
Scene Two: Teenagers in Macedonia
In the weeks following the 2016 election, journalists began tracing the origins of fake news stories: focusing on what stories were fake, who wrote them, how they went viral, and what motivated their production. Some stories were discrete instances—like, for example, the paid protestor story that originated with a tweet sent by Eric Tucker. That tweet went viral in 24 hours, eventually being endorsed by then-President-elect Trump (see fig. 4).
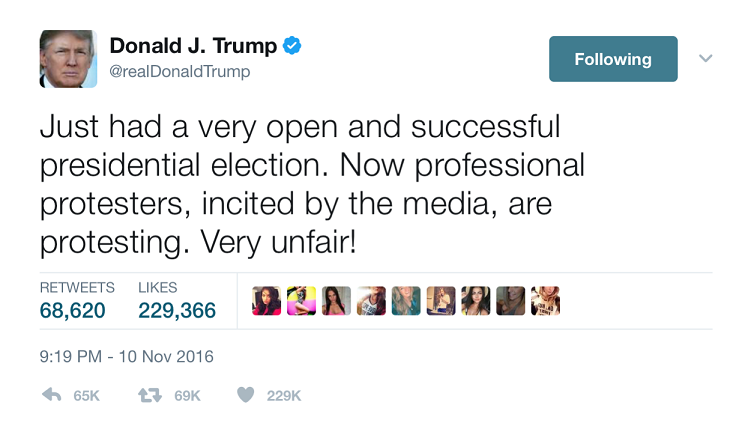
Figure 4: Trump’s endorsement of Eric Tucker’s paid protestor tweet.
Other stories revealed more intentional and systematic instances of the production and distribution of fake news through websites mimicking credible news outlets. Although some of this body of disinformation originated domestically through sites like ChristianTimesNewspaper.com (the site that circulated the bogus story about the discovery of fraudulent Clinton votes in a warehouse in Ohio), a group of Macedonian teenagers were responsible for a lion’s share of bogus stories that went viral during the 2016 election. BuzzFeed was one of the first to discover that the town of Veles, Macedonia—with a population of 55,000—was the registered home of more than 100 then-active pro-Trump websites and 40 inactive web domains referring to US politics (Silverman and Alexander). Upon closer examination, reporters discovered a cottage industry built on an existing digital infrastructure of social and advertising networks that a group of Macedonians repurposed to earn money “by gaming Facebook, Google, and Americans” (Silverman and Alexander). In principle, this group of savvy Macedonian teenagers were not doing anything new by publishing bogus stories for personal profit. For example, in 1835, Benjamin Day, publisher of the New York-based paper The Sun, ran a series of six bogus articles to boost the circulation of his paper. The six article series—now called the Great Moon Hoax of 1835—provided a detailed account of a vibrant ecology of living organisms on the surface of the moon that included descriptions of a variety of flora, fauna, and bat-men “covered, except on the face, with short and glossy copper-colored hair, and had wings composed of a thin membrane, without hair, lying snugly upon their backs.”
Although their goals are not new, what is noteworthy about this new generation of fake news makers are the literacies they developed and employed to meet their goal of making money through a digital economy of texts. Like the American students discussed in the previous section, these young entrepreneurs had developed a functional literacy needed to write and publish online, but these fake news makers’ functional digital literacies were more fully realized, allowing them to “distribute and access a wide variety of information (text, graphics, audio, video) globally, quickly, and relatively easily” from their phones and laptops (DeVoss and Porter 195). But more significantly, these writers had developed a set of critical, rhetorical, and information literacies that enabled them to use existing network infrastructures for their own monetary gain. Taken together, these three literacies enabled a group of teenagers in Macedonia to understand the socio-economic forces that shape networked information and to develop a reflective practice of circulating information online.
One of the Macedonian newsmakers was a teenager named Boris—a pseudonym—who was a focus of Samanth Subramanian’s Wired article on the Macedonian teenagers who momentarily turned fake news into a profitable industry. Utilizing a combination of Google’s AdSense program, Wordpress, and Facebook, Boris and his peers found new uses for these widely used and freely available platforms. Using Google’s AdSense program to monetize their Wordpress installations, Boris and his peers posted content only to circulate their ads—a strategy of earning income in the digital economy that they referred to as “AdSense work” (Subramanian). Boris, who Subramanian features in his article, was an 18-year-old who dropped out of high school after seeing the money-making potential of AdSense work, and in many ways his motivation bears resemblance to the students whom I’ve taught in first-year writing classes; Boris wants a BMW 4 Series, plays video games, likes rap music, wants a better cell phone, and wants more bar money. Seeing more potential in doing AdSense work than in working in a factory or a restaurant in Veles, Boris pursued AdSense work full-time. In terms of the payout for his efforts, Boris did well, outearning the average monthly salary in Veles of $371 by making nearly $16,000 from his two bogus pro-Trump websites between August and November of 2016. What makes Boris distinct from the novice-researchers discussed in the previous section are the medium-specific information literacies he cultivated to meet his goals. Specifically, Boris and the other AdSense workers intimately understood the relationships among platforms, information, and economics—a “critical literacy” that allowed them to undermine the original design of the AdSense program by prioritizing monetization over content creation—by treating content as the medium for the delivery of advertisements (Selber 81). Likewise, the AdSense workers also developed a “rhetorical literacy” that was essential to profiting from Google’s AdSense program: an understanding of the kind of content that would go viral and the kinds of audiences who would assist their articles in going viral (Selber 147).
Although Boris and the other Velesian teenagers made the news for their most recent efforts at AdSense work, Subramanian described a history of gaming the digital economy by crafting monetized, made-to-go-viral content for American audiences. He features, for instance, an account of Mirko Ceselkoski, who began building websites about celebrities, cars, and yachts for American audiences in the early 2000s. Subramanian notes that Ceselkoski was fairly successful, earning about $1000 a month through his AdSense work, but his bigger success happened in 2011, when Ceselkoski began teaching students to build and promote their own monetized websites. Two of Ceselkoski’s students, Aleksandar and Borce Velkovski, are well-known in Veles as the Healthy Brothers for their popular health food website, HealthyFoodHouse.com. Subramanian writes that
HealthyFoodHouse.com is a jumble of diet and beauty advice, natural remedies, and other nostrums. It gorges on advertising as it counsels readers to put a bar of soap under their bedsheets to relieve nightly leg cramps or to improve their red-blood-cell count with homemade beet syrup. Somehow the website’s Facebook page has drawn 2 million followers; more than 10 million unique visitors come to HealthyFoodHouse.com every month.
Not surprisingly, some of the Velesian teenagers who were key players in the Macedonian fake news fabrication business also studied with Celeskoski in 2016.
Following the model developed by Ceselkoski and perfected by his students, Boris initially began doing his AdSense work with two Wordpress-based sites called GossipKnowledge.com and DailyInterestingThings.com where he posted articles filled with sports, celebrity, health, and political news that he copied and pasted from websites across the internet. After he published a bogus story about Trump slapping a man that nearly went viral, Boris devoted all of his energy to circulating fake political news on his two newly-minted pro-Trump websites called PoliticsHall.com and USAPolitics.co. During this time, he worked on perfecting a strategy for making his story go viral by first publishing his fake news stories on one of his two websites and then sharing the link on Facebook either through his own profile or one of his 200 fake Facebook profiles. Additionally, to maximize his AdSense profits, Boris learned that more people would click on his ads if he embedded them between paragraphs, insuring that “one in five visitors” would click on an ad, which meant more income for Boris. In recounting this period of fake news making, Boris said his life revolved around trying to produce as many viral stories as possible:3
At night I would make four or five posts to share the next day. When I woke up, I shared them. I went to drink coffee, came back home, found new articles, posted those articles on the website, and shared them. Then I went out with friends, came back home, found articles, and shared them to Facebook. (Subramanian)
Boris and his friends’ efforts emphasize the power of technological discourse to normalize the possibilities of new technologies and imagine new practices. In Veles, where personal gain is emphasized over cultural benefits like the overthrow of the publishing regime (DeVoss and Porter) and the creation of participatory publics (Jenkins, Ford, and Greene), technologies are understood less as a means for facilitating democratic participation and more as a means of profiting from users. Put differently, Boris recognized that freely available technologies were created by companies to collect and profit from user data, and having recognized that reality, Boris employed a set of practices that enabled him to profit personally from an already-created network of hierarchical and monetized information (Selber 75). As Boris indicated, he utilized three platforms to profit from others: Google to find bogus articles, Wordpress to post his bogus articles, and Facebook to share his bogus articles. In each case, Boris used these platforms in ways that undermined the purposes of their design: in the case of Google, providing legitimate businesses with another revenue stream and in the case of Facebook, facilitating community-building. Through his deictic uses of Google and Facebook, Boris appropriated freely available tools designed to promote American values of entrepreneurship and democracy into a means of luring AdSense customers to sites with content posing as journalistic reporting.
Matthew Hindman, in his study of the relationships between infrastructures and democracy, concludes that search engine algorithms like Google’s PageRank have undermined the democratizing potential of the web. As Hindman has found, Google’s PageRank program and search engine algorithms like it have created a self-perpetuating hierarchy of internet traffic by rewarding the already-most visible sites with still more visibility: “Heavily linked sites should continue to attract more links, more eyeballs, and more resources with which to improve the site content, while sites with few links remain ignored” (Hindman 55). In tandem with an overwhelming concentration of the market between Google and Microsoft (“Latest Rankings”), search engines have ensured that while anyone can have a platform to speak online, very few are actually heard. In the realm of political discourse, this has created what Hindman refers to as “a new media elite” of familiar sites that receive the bulk of user traffic regardless of whether users get to the site by searching for a specific outlet or specific content (132). Such hierarchies are not created by search engines alone; Tarleton Gillespie has identified that Facebook’s algorithms also manipulate information that distort the “public discourse they host” (2):
Social media platforms don’t just guide, distort, and facilitate social activity—they also delete some of it. They don’t just link users together; they also suspend them. They don’t just circulate our images and posts, they also algorithmically promote some over others. Platforms pick and choose. (1)
Although the algorithms that drive Facebook’s feed are less known than Google’s search algorithms, what is known is that despite recent tweaks to the feed algorithms, Facebook posts with a higher engagement metric—a calculation of aggregate likes and time spent reading—tend to show up on more feeds (Oremus). In the same way that Google links are the metric for organizing information, desirability is the metric in a Facebook feed, so it is no surprise that posts are often designed to go viral by use of clickbait titles and hyperbolic claims. While Facebook’s hierarchy is created differently, it’s still a hierarchy with a similar effect: the prioritization of desirable information over accurate information.
As Kevin Brock and Dawn Shepherd have recently argued, this algorithm-created stratification of information is a strategy of persuasion employed by software companies to persuade their users while hiding from users that they have been persuaded: “we allow ourselves to be persuaded that we are the only agents involved in a particular situation when, in reality, there are networks of visible and invisible actors working to persuade us to specific ends” (21). The means of persuasion used by companies through their algorithms provides users with an expected event—like the discovery of information—to facilitate a second event that the user does not expect: the transformation of the user into a consumer through the monetization of their interests and browsing history (Brock and Shepherd 23). Put differently, Google’s system was created to turn their users into their consumers by way of their PageRank and AdSense algorithms. Facebook makes a similar rhetorical move by inviting users to provide data under the guise of forming a network—the expected event—in order to achieve their end of targeting advertisements to users—the unexpected event.
Boris’s use of these platforms suggests that he intimately understood the persuasive means and rhetorical ends of Google and Facebook in ways that technological discourse emphasizing the cultural benefits of these systems often do not. Like Google and Facebook, Boris turned his users into consumers while hiding that reality for his own financial gain, and he accomplished this goal through an effective set of practices reflective of network-specific critical and rhetorical literacies. First, he understood the economic realities of networks: how companies have monetized and created opportunities for consumers to monetize their information. Second, he learned more intimately who his audience is and what kind of content they want to read. Third, he learned where to post his articles on Facebook—in spaces where audiences distrust both the old mainstream media and the new, Googlized media elite. Fourth, he learned how to arrange the ads and content in his articles to maximize the number of ad clicks he could get on any one article through an intentional arrangement of his borrowed content and his AdSense ads. Put differently, Boris was a proficient remixer, skilled at employing the practices of assemblage and redistribution to achieve his goals. As Dustin Edwards has noted in his historical and typological account of remix, the re-use and transformation of existing works is intimately tied to the practice of imitation as a practice of invention (43). By imitating the look of news sites on his own domains and the discourse of hyper-partisan groups on Facebook, Boris persuaded people that he was both a reliable news outlet and a concerned citizen sharing information that the mainstream media would not. In so doing, Boris imitated the persuasive strategy of Facebook and Google by cultivating a consumer base without their knowledge of becoming consumers.4
Although Boris’s use of free technologies raises ethical, legal, economic, and political questions about the nature of information, networks, and platforms, this account of Boris’s AdSense work suggests that a more intimate understanding of the nature of networks and their corporatization is vital to information literacy. Within the context of a network that incentivizes desirable content over truthfulness, Boris and others doing AdSense work were skilled producers and distributors of discourse. Specifically, they were skilled at imitating the rhetorical strategy of the programmers who make free tools available to the public in order to profit from the public’s data. Although Boris and his peers were not making tools, they developed and enacted literacies that enabled them to find new uses for existing tools that were—to Boris’s credit—at odds with their original design. Wordpress was not designed to host Google ads, and Facebook was not designed to function as a space for the circulation of misinformation. Likewise, programs like AdSense and PageRank, as well as Facebook’s feed algorithms were not designed to incentivize clickbait. And more significantly, Google’s and Facebook’s algorithms were not designed to provide an opportunity for users to personally profit from their use. However, Celeskoski, the Nature Brothers, and Boris—among others—envisioned and successfully enacted new uses for these technologies to meet their own purposes. Boris was successful in meeting his own purposes precisely because he understood the economics underlying networked information, and this more complete understanding of the nature of networks allowed Boris to realize his goal, albeit through questionable means. While the practices these AdSense workers employed were disingenuous, the efficacy of their practices suggests the value of a technological discourse that includes the social and economic realities of networked information along with the possibilities entailed in the ability to write and publish for a global public.
Before closing, I outline an assignment designed to help students develop an information literacy that encompasses both a critical understanding of the nature of networks and the rhetorical possibilities of researching, writing, and distributing information online. While the following recommendation is informed by Boris’s AdSense work and the literacies entailed in that work, it deviates from Boris’s questionable ethics. Instead, these recommendations have at their center the mission of rhetoric to promote democracy and citizenship, or as Nancy Welch articulates, “understanding and teaching rhetoric as a mass, popular art—the practice of ordinary people who make up our country’s multiethnic, working-class majority, in their press for relief, reform, and radical change” (474, emphasis hers). To that end, the recommendation that follows is largely focused on the kinds of non-scholarly texts that Boris assembled, published, and redistributed. The reason for this focus on non-academic writing is twofold: first, as the Stanford History Education Group report shows, students are underprepared to evaluate texts not traditionally housed in library holdings, which are the overwhelming majority of texts that circulate online. Second, in keeping with the commitment to teach rhetoric as the practice of ordinary people, these recommendations also gesture to everyday instances of research—what David Barton and Mary Hamilton refer to as “sense making” (231)—that people practice to solve practical problems and promote personal change. Because such research most often involves non-academic texts and often occurs informally where the mechanisms for reflecting upon and evaluating knowledge are also informal, the development of a useful information literacy must include sense making with nonacademic texts.
There are a wealth of strategies, practices, heuristics, and checklists available online and in writing handbooks designed to help students assess the credibility of information during research. As noted previously, Mike Caulfield's textbook, Web Literacy for Student Fact-Checkers, stands out among an already-staggering body of materials because unlike other materials, Caulfield's book provides a set of strategies for finding what's true online in a manner reflective of the nature of networked information:
We will show you how to use date filters to find the source of viral content, how to assess the reputation of a scientific journal in less than five seconds, and how to see if a tweet is really from the famous person you think it is or from an impostor. We'll show you how to find pages that have been deleted, figure out who paid for the web site you're looking at, and whether the weather portrayed in that viral video actual matches the weather in that location on that day. We'll show you how to check a Wikipedia page for recent vandalism, and how to search the text of almost any printed book to verify a quote. We'll teach you to parse URLs and scan search result blurbs so that you are more likely to get to the right result on the first click. And we'll show you how to avoid baking confirmation bias into your search terms.
By acknowledging the variety of purposes and texts that circulate online, Caulfield's book helps students develop an information literacy that resembles the literacies Boris employed to deceive readers for his personal gain. In other words, the goal of Caulfield's book is to help students understand—like Boris—the economic and political realities of networked information. Using Caulfield's book as a guide for understanding the variety of information online and how to assess that information for credibility, this assignment asks students to apply Caulfield's strategies through the use of a social annotation platform to collaboratively annotate a set of texts to determine their credibility.
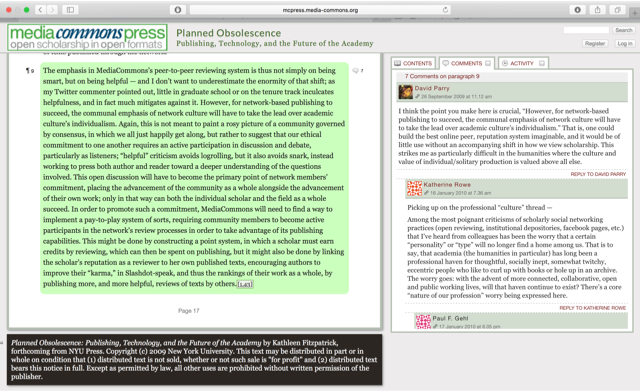
Figure 5: Screenshot of a selection from Kathleen Fitzpatrick's Planned Obsolesence pre-published through the MediaCommons Press.
In digital humanities circles, social annotation has taken hold as a method of evaluating, commenting, and providing feedback on texts in process in order to explore and enact new models of scholarly publishing through a peer-to-peer and consensus-driven approach to peer review. Venues like MediaCommons Press (http://mcpress.media-commons.org) and MLA Commons (https://mla.hcommons.org) reimagine scholarly publishing as a network where readers can provide writers feedback and critique on unfinalized manuscripts. Elsewhere, web designers have used Genius, a web-based social annotation platform, to annotate texts through a Chrome extension or through the Genius.com website where readers annotate literature, news stories, and lyrics. In my own classes, I have asked students to use social annotation platforms to call their attention to the social dimensions of reading, the relationship between technologies and meaning making, and the role of past-experience in meaning making. Using a platform like the Hypothes.is (http://hypothes.is) browser extension, students form collaborative groups and comment on a reading in a shared web environment. Although the students' takeaway from this activity varies according to the nature of the class and the nature of the assignment, social annotation provides students an opportunity to put into practice theories of meaning making by defamiliarizing routine behaviors involved in reading for class. For this assignment, the social annotation tool has two purposes. First, given the sometimes-complex nature of information that circulates online, the collaborative assessment of information provides opportunities for students to learn from their peers the many forms that both incredible and credible information can take and the potential indicators of incredible information. Second, because the texts most likely to misinform or deceive students come in genres that students encounter every day, a social annotation platform helps make the familiar unfamiliar. By helping to defamiliarize everyday genres like social media posts, social annotation complements the goal of helping students more carefully examine the texts that appear in their research projects and shape their everyday lives.
Insofar as networks have impacted scholarly research by making previously-hidden texts and sites publically available, so too have networks impacted—and continue to impact in new ways—the literacies needed for civic participation. In an age where the President of the United States tweets policies at 3AM and teenagers in Macedonia who were trying to supplement their income undermined the Fourth Estate, technological discourse that is agnostic to differences among media no longer suffices. Likewise, given the still-evolving and deictic nature of technology, observing the nature of information in a current moment is key to students' development of information literacies. The approach I have outlined above—analysis of texts that students find, use, and value when conducting research—helps them come together to observe and analyze "the contours and the changing dynamics of the world of information" that informs our research and our democracy (ACRL). As information continues to change as a result of new goals, new technologies, and new uses for existing technologies, students' developing literacies and technological discourses should reflect the changing nature of the technologies that have become integral to academic contribution and democratic participation.
Endnotes
1Hunt Allcott and Matthew Gentzknow have recently released findings from a study, "Social Media and Fake News in the 2016 Election," in which they argue that fake news was not a determining factor in the outcome of the 2016 presidential election.
2 Caulfield's book was featured recently as the Digital Rhetoric Collaborative's Webtext of the Month for April, 2017. As part of the feature, Kristin Ravel interviewed Caulfield about the project.
3 After the election and with the emergence of new systems for flagging misinformation shared online, Boris abandoned his two existing sites and has not yet developed a plan for a topic of focus for his future AdSense work.
4 It is also worth noting that the news Boris shared was not originally his: it was always a compilation of existing information redistributed through one of his websites and Facebook profiles.
Works Cited
Allcott, Hunt, and Matthew Gentzkow. "Social Media and Fake News in the 2016 Election." Journal of Economic Perspectives 31.2 (2017): 211-36. Print.
Association of College & Research Libraries Board. "Framework for Information Literacy for Higher Education." Association of College & Research Libraries (ACRL). Association of College & Research Libraries (ACRL), 11 Jan. 2016. Web. 9 June 2017.
Barton, David, and Mary Hamilton. Local Literacies: Reading and Writing in One Community. London: Routledge, 1998. Print.
Brock, Kevin, and Dawn Shepherd. "Understanding How Algorithms Work Persuasively Through the Procedural Enthymeme." Computers and Composition 42 (2016): 17-27. Print.
Caulfield, Michael A. Web Literacy for Student Fact Checkers. Pressbooks, 2017. Web. 9 June 2017.
ComScore. "Explicit Core Search Share Report (Desktop Only)." ComScore, Inc. ComScore, Inc, Apr. 2017. Web. 9 June 2017. www.comscore.com/Insights/Rankings.
"Crossfire (TV series)." Wikipedia, The Free Encyclopedia. Wikipedia, The Free Encyclopedia, 1 May. 2017. Web. 15 June 2017.
D'Angelo, Barbara J., Sandra Jamieson, Barry M. Maid, and Janice R. Walker, eds. Information Literacy: Research and Collaboration across Disciplines. Fort Collins: WAC Clearinghouse, 2017. Print.
Devoss, Danielle Nicole, and James E. Porter. "Why Napster Matters to Writing: Filesharing as a New Ethic of Digital Delivery." Computers and Composition 23.2 (2006): 178-210. Print.
Edwards, Dustin W. "Framing Remix Rhetorically: Toward A Typology of Transformative Work." Computers and Composition 39.1 (2016): 41-54. Print.
Felker, Alex. "Jon Stewart on Crossfire." Online video clip. YouTube. YouTube, 16 Jan. 2006. Web. 9 June 2017.
Gillespie, Tarleton. "Platforms Intervene." Social Media Society 1.1 (2015): 1-2. Print.
Gocsik, Karen, Laura R. Braunstein, and Cynthia E. Tobery. "Approximating the University: The Information Literacy Practices of Novice Researchers." Information Literacy: Research and Collaboration across Disciplines. Eds. Barbara J. D'Angelo, Sandra Jamieson, Barry M. Maid, and Janice R. Walker. Fort Collins: WAC Clearinghouse, 2017. 163-84. Print.
"The Great Moon Hoax." Museum of Hoaxes. Museum of Hoaxes, nd. Web. 09 June 2017.
Hindman, Matthew. The Myth of Digital Democracy. Princeton: Princeton UP, 2009. Print.
Jenkins, Henry, Sam Ford, and Joshua Green. Spreadable Media: Creating Value and Meaning in a Networked Culture. New York: New York UP, 2013. Print.
Kress, Gunther, and Theo van Leeuwen. Reading Images: The Grammar of Visual Design. London: Routledge, 1996. Print.
Landow, George P. Hypertext 3.0: Critical Theory and New Media in an Era of Globalization. Baltimore: John Hopkins UP, 2006. Print.
McCorkle, Ben. Rhetorical Delivery as Technological Discourse: A Cross-Historical Study. Carbondale: Southern Illinois UP, 2012. Print.
Millstein Undergraduate Library. "Evaluating Online Sources." Columbia University Libraries. Columbia University Libraries, 2017. Web. 9 June 2017, www.library.columbia.edu/locations/undergraduate/evaluating_web.html.
Oremus, Will. "Who Really Controls What You See in Your Facebook Feed—and Why They Keep Changing It." Slate Magazine. The Slate Group, 3 Jan. 2016. Web. 9 June 2017.
Porter, James E. "Recovering Delivery for Digital Rhetoric." Computers and Composition 26.4 (2009): 207-24. Print.
Selber, Stuart A. Multiliteracies for a Digital Age. Carbondale: Southern Illinois UP, 2004. Print.
Silverman, Craig, and Lawrence Alexander. "How Teens in The Balkans Are Duping Trump Supporters With Fake News." BuzzFeed. BuzzFeed, 03 Nov. 2016. Web. 9 June 2017.
Stanford History Education Group. Evaluating Information: The Cornerstone of Civic Online Reasoning. Stanford Digital Repository, 22 Nov. 2016. PDF file.
Subramanian, Samanth. "The Macedonian Teens Who Mastered Fake News." Wired. Conde Nast, 15 Feb. 2017. Web. 9 June 2017.
Trump, Donald J. (@realDonaldTrump). "Just had a very open and successful presidential election. Now professional protesters, incited by the media, are protesting. Very unfair!" 10 Nov. 2016, 6:19 PM. Tweet.
Wineburg, Sam, and Sarah McGrew. "Why Students Can't Google Their Way to the Truth." Education Week. Editorial Projects in Education, 1 Nov. 2016. Web. 9 June 2017.
Welch, Nancy. "Living Room: Teaching Public Writing in a Post-Publicity Era." College Composition and Communication 56.3 (2005): 470-93. Print.
Yancey, Kathleen Blake. "Creating and Exploring New Worlds: Web 2.0, Information Literacy, and the Ways We Know." Information Literacy: Research and Collaboration across Disciplines. Ed. Barbara J. D'Angelo, Sandra Jamieson, Barry M. Maid, and Janice R. Walker. Fort Collins: WAC Clearinghouse, 2017. 77-91. Print.
---. "Made Not Only in Words: Composition in a New Key." College Composition and Communication 56.2 (2004): 297-328. Print.