Abstract
Literacy researchers might develop a richer understanding of how literacy practices construct communities and writers within those communities through more detailed attention to what writers do when they write. Very little is currently known about the processes by which individuals are actually composing in digital writing environments. However, in this cultural moment of sweeping social, linguistic, and technological literacy transformations, research on digital composing processes involves unique methodological challenges. Contemporary writing technologies intersect with digital literacy composing processes in ways that require critical ethical and methodological decision-making by literacy researchers at all stages of the research process. In this article, I argue that research on contemporary composing processes provides a crucial window onto literacy as a social practice, and further, that such research poses unique methodological challenges for researchers. Through an examination of Facebook writers’ composing processes, I articulate some of these challenges and offer guidance for future research.
Keywords: research methods, composing process, Facebook, social media
Contents
Methodological Challenges of Digital Literacy Composing Practices
Data Collection Methods for Capturing Digital Literacy Composing Processes
Composing Analyzable Data Sets of Digital Literacy Composing Processes
Unanticipated Participants and Peripheral Data
Kairos and Strategies for Studying Digital Literacy Composing Practices
Introduction
Research on literacy as a social practice of everyday life has contributed much to composition scholarship in its understanding of the larger contexts in which writing (and written composition) are situated. New Literacy Studies—which focuses on “the full range of cognitive, social, interactional, cultural, political, institutional, economic, moral, and historical” contexts for the study of literacy (Gee 2) —has paid systematic attention to the meaning-making activities of literate practice within complex social situations. In response to the earlier autonomous model of literacy, New Literacy Studies revealed literacy to be “part of a complex ideology, a set of specific practices constructed within a specific infrastructure and able to be learnt and assimilated only in relation to that ideology and infrastructure” (Street 180). A robust body of research has provided richly detailed theoretical and empirical understandings of literacy as a situated social practice, because as David Barton argues,
to understand literacy, researchers need to observe literacy events as they happen in people’s lives, in particular times and places. The fact that different literacies are associated with different domains of life means that this detailed observation needs to be going on in a variety of different settings, and also that findings from one setting cannot simply be generalized across contexts. Research needs first to be specific to a given domain, before making any general claims about literacy. (52)
Researchers interested in observing literacy events as they happen in people’s digital lives face new challenges, however, in capturing and understanding what people do with literacy in online spaces and how those practices coalesce with lives offline. Increasingly, this understanding of digital literacy practices is relevant across all domains of people’s lives (educational, civic, workplace, and social) and crucial to a fuller understanding of literacy and the broader social goals and cultural practices these literacy practices help to shape.
Methodologically, there has been a heavy emphasis on ethnographic studies in NLS research. This methodological homogeneity is of course intimately connected to the NLS insistence that literacy be studied as a local practice. This research orientation was best supported through an ethnographic approach to literacy as it is practiced in situ (indeed, Brian Street’s foundational NLS text, Literacy in Theory and Practice, is as much an argument about literacy methods as it is a theorizing of literacy as a socially situated practice). I believe that composition researchers have the potential to expand NLS scholarship in a significantly meaningful way by providing a needed piece of the literacy puzzle through our focus on composing processes situated within literate practices. Ethnographic research has revealed the great variability of literacy throughout human experience, and at the same time, it has suggested the inadequacy of a singular methodological approach to capturing such a complexly and deeply situated practice of meaning making. While ethnographic approaches are good at capturing large cultural phenomenon and their significance and meaning for groups of people, composition studies researchers have paid more fine-grained, systematic attention to the composing processes of writers through a variety of research methods:
- think aloud protocols (Berkenkotter; Flower and Hayes, “Cognitive” and “Cognition”; Perl; Smagorinsky, “Writer’s Knowledge”; Smagorinsky, Daigle, O’Donnell-Allen, and Bynum; Takayoshi)
- interviews (Faigley and Hansen; Miller; Odell and Goswami; Rose)
- observations (Berkenkotter and Murray; Castelló, Iñesta, and Corcelles; Haas Dyson; Jensen and DiTiberio; Pianko; Selzer)
- time-use diaries (Buck; Hart-Davidson; Pigg; Grabill et al.)
- multi-draft comparisons of texts (Collier; Flynn; Schwartz; Sommers)
In these studies, composition studies researchers have captured the composing processes of a diverse range of people: academic writers (including undergraduates, graduate students, and faculty), professional writers, and everyday writers.
This methodological variety provides a range of perspectives on literacy as it is practiced. An ethnographic understanding of literacy as a cultural phenomenon, coupled with composition studies’ research on individual writers at the moment of composing, provides a richer understanding of literacy as a situated practice than either does alone. This coupling of methodological approaches may go some way toward addressing Deborah Brandt and Kate Clinton’s contention that the localized study of literacy “created methodological and conceptual impasses that make it hard to account fully for the working of literacy in local contexts” (338). Drawing on the rich history of methodological approaches in composition studies, researchers might begin “to bring the ‘thingness’ of literacy into an ideological model” (Brandt and Clinton 256). Through a diversity of research approaches, literacy researchers might develop a richer understanding not only of how literacy practices construct communities and writers within those communities, but in turn, of how writers are using the “thingness’ of literacy to construct the communities and their identities within those communities through literacy. These methodological concerns are of utmost importance in this cultural moment of sweeping social, linguistic, and technological literacy transformations. Emerging and still-to-emerge writing technologies intersect with research on contemporary digital literacy composing processes in ways that require critical ethical and methodological decision making by literacy researchers at all stages of the research process (that is, at the research design, data collection, analysis, and representation stages). In this article, I articulate some of these serious challenges researchers face in examining contemporary practices of literacy. We currently know very little about the processes by which individuals are actually composing in digital writing environments. I argue that research on contemporary digital literacy composing processes provides a crucial and needed window onto literacy as a social practice, and, further, that such research poses unique methodological challenges for researchers.
Methodological Chalenges of Digital Literacy Composing Processes
In the introduction to their wide-ranging collection on digital writing research methods, Heidi McKee and Danielle Nicole DeVoss argue that “[d]igital technologies and the people who use those technologies have changed the processes, products, and contexts for writing and the teaching of writing in dramatic ways—and at this cultural, historical, and intellectual moment, it is imperative that our research approaches, our methodologies, and our ethical understandings for researching adequately and appropriately address these changes in communication technologies” (11). Chapters in their collection address multiple practical as well as ethical issues that experienced researchers have negotiated in digital writing research, providing an introductory understanding of changes that will only continue to evolve; as Susan Herring has also recognized, “new media pose special methodological challenges” (51), particularly “the range of challenges raised by analysis of new media content, including issues of definition, sampling, and research ethics, and the often times innovative solutions found to address them” (48). As McKee, DeVoss, and Herring recognize, researchers of new media have often found little guidance for how to work practically, analytically, and ethically with emerging forms of communication, often being required to come up with “innovative solutions” to the challenges. Certainly any research practice is likely to involve innovative thinking in order to capture accurately the specific contextual nuances of the particular research question; however, there is currently little methodological guidance even for how to begin navigating the challenges of research design, field work, and analysis involving new media data. Very often, the innovative solutions adopted to address the challenges are not included in the report of research findings and conclusions. Through my work on several research projects, work with other researchers in graduate courses on research design and field methods, and more focused one-on-one work with dissertating researchers negotiating the challenges of new media projects, I have experienced and witnessed many of the challenges and innovative solutions that are essentially written out of the final representations to which audiences have access. In this article, I draw on multiple experiences researching new technologies and writing in writers’ every day lives:
- My multi-year involvement on a research team investigating the composing of Facebook writers revealed that research on digital literacy composing can require the creative development of new data collection practices and analytic procedures for digital literacy composing process data. The eight-member Facebook research team1 asked How do writers compose in networked, multimodal, interactive social spaces for written communication? Specifically, we were interested in what writers do when they write online, what writers think about the writing they do, and how writers engage with their audiences in the writing they do in interactive networked spaces. Over the course of two years, we collected and analyzed eight writers’ processes of public and private writing in Facebook through screencasts (screen capture videos accompanied by the writer’s think-aloud protocol), resulting in 21,298 word transcript from the think-aloud protocol data and an additional 15,000 words describing the screen capture.
- My multi-year involvement on a research team investigating instant messaging revealed that participant selection and participant consent can be a complicated matter in new media contexts, particularly as it involves what I discuss below as “peripheral participants.” The IM project revealed the ephemeral characteristics of digital literacy composing that require researchers to create contextually derived methods of data collection and participant selection. The IM research team asked What forms does the writing in IM take? What are writers doing to and with written language in IM? Over the course of three years and many hours of face-to-face and virtually connected analytic discussions, our research team worked together to analyze, categorize, and make sense of 54 IM conversations involving 32,000 words of data set and ended up with a taxonomy of written language features.
- Over the last ten years, I have taught five sections of graduate courses in Research Design and Field Methods to fifty or so graduate students. These courses have allowed me the opportunity to read, think, and discuss with many careful thinkers the challenges of research practice. In these courses, I have been given the opportunity to dive deeply with an informed and curious team of beginning researchers into methodological theories and the practical shape and consequences of research (with students working as a whole-class research team on an authentic research question or working as individual researchers on their own self-defined research projects). Additionally, through directing 17 dissertations at two universities and serving on 57 dissertation committees at numerous universities, I have worked with researchers adopting a range of methodological approaches in many different research sites, with a variety of participant populations, through the lens of a diverse range of specific research questions. New researchers often, through their explorations of (what are to them) unfamiliar waters, uncover the challenging methodological moments where researchers must make kairotic decisions situated within the unique study. It is impossible to estimate the influence these beginning researchers and emerging scholars have had on my thinking about research, but it is important to acknowledge the tremendous influence they have had on my tacit understandings of research practice, many of which take explicit form in this article.
This “strategic contemplation” draws attention to the unseen ways in which this work (like so much research-based work) is “also embodied, grounded in the communities from which it emanates” (Royster and Kirsch 659). As Cressida Heyes and other feminist research methodologists have insisted, our personal commitments and experiences “are, as always, deeply intertwined with the structure of [our] arguments” (1096). A network of research projects, practices, and fellow researchers have tacitly and explicitly contributed to this article. Across these experiences, I have come to understand that research on digital literacy composing presents unique but not insurmountable methodological difficulties.
Many researchers have written about ethical quandaries experienced in the conduct of fieldwork (Bain and Nash; Halse and Honey; Jacobs-Huey, Powell and Takayoshi; Taylor and Rupp). However, little has been written about the ways composing technologies give rise to dissensus at the research design and analysis stages of research. Unlike the methodological challenges researchers might encounter in their work with people in the field (challenges that often arise from individual personality and human interaction), the challenges researchers face at the research design and data analysis stages arise as problems of the very process of researching online at the moment of composing. Using examples from these various research projects in which I have been involved, in this article, I focus on three unique concerns that digital literacy composing processes pose for researchers:
- At the research design stage, data collection methods must be assessed for how closely they capture composing processes.
- After these (often multimodal) data sets have been collected, researchers must attend to composing analyzable data sets of digital literacy composing.
- In analysis, researchers face the ethical problem of what to do with unanticipated participants and peripheral data collection.
These three methodological challenges are not ones uniquely arising from a particular study of a particular site; instead, they are challenges common to any research on digital composing. Describing these methodological challenges that researchers face, in the following sections, I provide some guidance for researchers in navigating these challenges.
Data Collection Methods for Capturing Digital Literacy Composing Practices
Researchers might collect data that is separate from the activity of composing (as in interviews and surveys that ask writers to talk about composing experiences they’ve had previously) or, at the other end of the spectrum, data that occurs more closely to the moment of composing (as in screen capture video that records the actions taken in a computer program or eye tracking videos that record the participant’s visual pathways). Thus, data collection methods aimed at understanding composing might be understood in terms of their proximity to the moment of composing as well as their ability to provide a more or less partial understanding (Figure 1).

Figure 1. Proximity of data collection to moment of composing relative to the method’s ability to provide a more or less partial understanding.
As this figure shows, in studies of digital literacy composing, data collection practices vary in terms of their proximity to the composing activity: from practices distanced from the moment of composing (surveys, interviews, focus groups, other forms of participants’ self descriptions) to practices grounded in the moment of composing (think-aloud protocols, screencast videos, video recordings of computer windows, eye tracking videos) with numerous data collection methods between (screen captures, comparison of multiple written drafts, retrospective interviews grounded in think-alouds or video screencasts). Figure 1 shows that these data collection practices can be understood in terms of how nearly they move toward a comprehensive understanding of the writing process. The more one’s study brings together multiple perspectives, the less partial and more detailed the understanding: while a survey alone can give a sense of what writers think or report they do when they write, coupling that partial understanding with screen captures or comparisons of written drafts can provide a measure of how closely a writer’s understanding of her process and her actual composing practices match. Particularly with research located closer to the act of composing, research that combines methods (for example, screen capture or eye tracking with think-aloud or retrospective verbal protocols) can move toward a fuller (yet always impartial) understanding of what writers are doing and their decision making processes.
The increasing ubiquity of digital composing technologies allows contemporary researchers to situate their data collection close to the moment of composing. We are in the unique position historically to capture exactly what happens when writers write. In particular, screen shot and screen capture programs provide an important view of the work writers undertake on computers. Screen shots of different stages in a composition allow us to see changes in compositions over time, and retrospective interviews focusing on those screen captures allow researchers to direct participants’ reflections on particular moments in the composing process. Screen shots do not allow us to see how those changes took shape, however, in the way that screencast programs create a digital recording of changes over time on a computer screen made by a participant as she works (when coupled with a writer’s audio narration, screencast recordings become even richer data sets). Recording a writer’s think-aloud protocol as the soundtrack for the screencast video allows researchers to see the composition unfold as a movie and to have the composer’s thinking synchronized to the particular stage in the process. Particularly with multimodal, digital literacy composing, a writer’s descriptions of her writing process may serve as necessary but not sufficient data – composing with computers often moves so quickly that writers are unable to describe every detail, writers may not understand the significance of steps in their process that literacy researchers find meaningful, and a writers’ description of her composing may not accurately communicate what is actually happening. As social theories of technology remind us, technologies work best when they are invisible.
A particularly rich example of this is a participant in the Facebook research project I described above. In his think-aloud screencast, Bill says “Maybe I should make a new profile picture” and then proceeds to select a photo from his Facebook photo album, import it into Adobe PhotoShop, and edit it into a practically new composition, while also continuing two chat conversations and checking his Facebook Wall as notifications alert him to new postings. With breathtaking speed and facility, Bill completes 99 unique commands in just seven minutes—from the relatively straightforward process of selecting a photo to the more complicated and multilayered processes of editing the photo, all involving their own series of cursor movements, selections, and commands. After opening a new file in Photoshop, Bill copies the selected image from Facebook into Photoshop, selects the part of the image he wants to retain, changes the image hue, blurs the image, changes the lighting of the image, writes “Cold Chillin” on a new Photoshop layer so it is imposed onto the image, justifies and edits the font of the text, saves the image, copies the image from Photoshop back into Facebook, and tags the five people in the photo. Within each of these composing acts, Bill makes numerous decisions and completes multiple commands, announcing with finality “Done” once the photo has been published as his profile picture and people in the photo tagged.
Behind this writer’s rumination that “Maybe I should make a new profile picture” are nearly a hundred unidentified processes involved in the composing that would be elided in a comparison of the final products (i.e., the original and final edited profile photos). Significantly, even Bill’s think-aloud protocol alone barely begins to capture the discrete steps involved in the composing process. His think-aloud protocol references his thinking in only the broadest terms: “put it left of the line. Get a better font. Something more bold and in your face. Arial Black.” In the retrospective interview (focused on specific moments in the screencast), when asked if he had a plan for the photo before he started editing it, Bill says,
Usually when I’m editing a photo for a profile picture, I, sometimes I’ll have something in mind and I’ll think through like how I’m going to do it, and then I’ll do it. And then sometimes, it’s just like, I’ll just open up Photoshop and start doing random things, and like, ‘Oh, that turned out good.’ And I’ll use it. …. I just know different things will make different effects so I just started doing them. I didn’t have anything in mind for it when I did this.
Bill suggests that sometimes he has a plan before he begins the composing and editing of his profile picture, but that in this case, he didn’t have anything in mind when undertaking the 99 commands (the “random things” he did) to compose his profile picture. Bill’s expertise with Photoshop may mask for him the complexity of the steps he undertakes in editing the photo. When he’s asked how he keeps all the multiple actions straight while he’s moving through them at such speed, he replies, “Well, I’ve been doing this for a long time. I can’t explain that any other way. I mean, I’ve worked with computers since I was like eight.” In both his think-aloud and his retrospective interview, Bill’s descriptions of his process very much downplay its complexity. It is only through having a multi-tiered data set—think-aloud, screencast, and focused retrospective interview—that researchers can begin to see the complexity of his composing process. If we are to understand digital literacy composing, researchers need ways to capture, analyze, and represent the multiple modes of composing with an awareness of how those different modes of composing relate to and intersect with one another.
As Bill’s case shows also shows, as with any research question, certain forms of data and data collection are more apt than others for answering particular research questions. Data collection separated from the moment of composing is more appropriate for studies of writers’ attitudes toward and beliefs about their digital literacy composing: such data collection methods focus on writers’ self assessment and do not capture what writers actually do in the act of writing. On the other hand, data collected more closely to (and during) the moment of composing is more fitting for studies not on writers’ perceptions but on the activities in a writer’s processes (some of which may be tacit, as they are for Bill, and thus unrecognized by the writer). Cheryl Geisler and Sean Slattery suggest that for literacy researchers committed to “process tracing” (that is, capturing writing processes in the moment of composing), video screen capture provides a way of recording and understanding the complexity of moment-by-moment composing in digital environments: “Video screen capture has thus made visible phenomena that might otherwise have gone unnoticed in digital writing” (187). Making visible what has “gone unnoticed in digital writing” can meaningfully add to a well-begun understanding of what writers say and think about their processes by providing a window onto what they actually do when they compose—what types of planning take place, how drafting proceeds, when revision occurs, how writers move between different composing programs, what instigates that movement, and myriad other composing process questions that remain unexplored. This research requires contextual decision-making about how researchers will capture writers’ composing processes (through hard copies of stages in a process, still screen capture images, screen capture video, screencasts, think-aloud protocols, retrospective interviews, or some combination of these methods) as well as how these various modes of data combine to create a picture of digital literacy composing. In the following section, I discuss the reliable construction of multilayered data representations of composing processes.
The process of ordering data, of course, occurs throughout the entire research process: from the research question and design we first articulate (in which we choose our question and design, filtering out other possibilities) to the data collection (in which we do not—cannot—capture every detail but focus on what is most pertinent) to the ordering of collected data into a manageable form which can be systematically analyzed (the arrangement, and repeated rearrangement, of disordered data into a coherent form destined to be categories of meaning and analysis). The first step in creating an accurate representation almost always involves some form of transcription or ordering of written data, and ordering and transcribing collected data into a manageable form is more than mere labor in preparation for analysis. Instead, transcription is the first step in the analytical writing process; it is the first act of writing in that researchers are translating into written language our interpretation of the raw data.
Describing transcription as “an interpretive process and as a representational process,” Judith Green, Maria Franquiz, and Carol Dixon point out that “a transcript is a text that ‘re’-presents an event; it is not the event itself. Following this logic, what is re-presented is data constructed by a researcher for a particular purpose, not just talk written down” (172). The researcher, in other words, shapes the data through the act of transcription. Very often, though, transcription is treated as a mechanical matter of merely translating oral data into written form. I believe that it is important to interrogate transcription as an interpretive act of writing because as researchers well know, writing functions as a mediational means and constructs as well as captures “reality.”
The transcription stage in the research process is often idiosyncratic because the raw and constructed data are usually only seen by the researcher (or if she’s on a research team, her colleagues; or if he’s writing a dissertation, perhaps his dissertation director). The goal for creating a coherent data set is making the raw data manageable and analyzable—that is, getting the raw data into a form that allows for analysis of it. Add to this the complexity of multimodal (or extra linguistic) data and the transcription of data becomes complex, with little published scholarship available to guide researchers’ decision making. The construction of multimodal data sets often involves researchers of multimodal composing processes thinking creatively and carefully about what data they want to analyze, the relationships between the multiple modes of data, and what needs to be represented about those modes and relationships.
While the transcription (nailing down of a moment in time) of sound and image may be easily guided by existing models of transcription, video and particularly its corresponding recording of movement present new methodological challenges. In a multimodal environment, for example, cursors move rapidly as users navigate through a single screen, screens move up and down as users scroll through pages in a program, programs layer one on top of the other as users move between multiple open programs, and written utterances are recursively composed with letters entered, deleted, entered again. Developing a transcription system that renders audio (think-aloud) and visual (screen capture) data into a coherent, linguistic form was crucial for the Facebook team’s movement from raw data to codifiable data set. As Figure 2 demonstrates, capturing and codifying a writer’s composing in Facebook involved transcribing two types of data: verbal think-aloud protocols and visual screen capture video. Either one alone would provide a partial (and likely, confusing) picture of the complexities of reading, writing, navigating, responding, initiating, and reflecting involved in composing in the multimodal and multilayered technological world of Facebook. As Figure 2 shows, transcribing the process involved transcribing the audio data of the think-aloud protocol in synchronization with the video data of the screen capture.
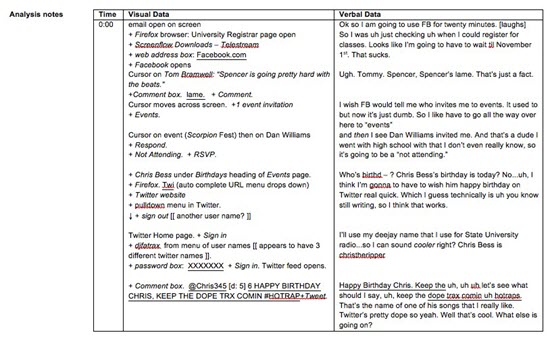
Figure 2. Screencast transcription.
Our synchronization of the visual and audio data is an example of the ideological shaping of our data set in relationship to our research objective: developing a data-rich picture of writers composing in Facebook. Our emphasis was on the composing process, not the textual products as they evolved over time, and so we had to account for the keystrokes to accurately capture all that writers did when they wrote using their computers. We needed to capture the specific actions participants made in the interface as well as their thoughts about those actions. Additionally, as capturing the writers’ movement in the environment is crucial to understanding the composing going on there, our research team was faced with developing a way of linguistically capturing cursor movement, the selection of interactive buttons and links, movement of the screen (as the composer scrolled up and down reading through the page), movement between parts of the interface (from Wall post to private chat, for example), and the production of written text.
Once we had agreed upon a consistent form for transcribing the data, we transcribed the data (approximately 36,000 transcribed words total; 21,000 in the think-aloud protocols alone), with every transcription in the Facebook project reviewed by another team member. This second round of transcription allowed us to catch inaccuracies, misinterpretations, and details that the original transcriber missed, because as Kristen L. Easton, Judith Fry McCormish, and Rifka Greenberg recognize, “As a general rule, just as an analysis can only be as accurate as the person doing it, so also is a transcription only as precise as the person transcribing. Having people on the team who are invested in the project and committed to accuracy at every phase is essential to the integrity of the study and necessary for establishing dependability and confirmability” (707). The second round of transcription sometimes led to revisions in the transcriptions that significantly altered the meaning, but more importantly, having the transcriptions reviewed worked much the way interrater reliability measures the reliability with which the data can be understood in the way it was understood by the initial researcher. If we believe that transcriptions are the first analytical step in a research project, producing the first written form of the data, then it makes sense that even at this early stage in the research process, we build in measures of accountability and reliability. Theories of reliability suggest that a measure (or in this case, an interpretation in the shape of a transcription of data) is considered reliable if it gives the same result over and over again, particularly from the perspective of multiple people (or raters). Rather than seeing a second round of transcription as a corrective for accurate transcription, we might instead understand this second round of transcription as a check for reliability of the important first stage of analysis (thus shifting our conception of transcriptions from technical, lower order skill to analytic, meaning-making work).
Multimodal data sets such as screencasts require that researchers not lose sight of the uniquely and definitively multimodal nature of the data. Researchers cannot rely solely on the linguistic rendering but must always be moving back and forth between visual and verbal data. The linguistic rendering is not about meaning but about methodological process: it is not a more accurate rendering of the phenomenon but rather a methodological necessity. By creating a linguistic re-representation of the verbal and the visual, we create a workspace where we can begin to identify what happens, what’s interesting, how the verbal and visual are interlocked, and the patterns that exist in the data. All the way through that process of understanding, though, researchers need to be moving back and forth between the linguistic visual/verbal transcript and the video data in order to not lose sight of the essence and features of the visual data and to not mistakenly let the linguistic stand in place of the visual.
Unanticipated Participants and Peripheral Data
In addition to being attendant to data collection and constructing a reliable data set, researchers must pay careful attention to ethical issues involving research participants and consent. Increasingly, literacy in online space is intensely interactive, as people collaboratively write the digital space, slipping seamlessly back and forth between writer and audience roles. The intertextual nature of literacy, as well as the numbers of people dispersed through time and space, create a likewise amorphously bounded research population. Research on composing practices in interactive social networked spaces involve researchers in a web of potential participants as singular writers interact synchronously as well as asynchronously with multiple other writers.
In methodological theory and research design guidebooks, participants in qualitative research have largely been assumed to be identifiable people the researcher has chosen to participate. Research on literacy as a social practice, however, expands the boundaries of the activity of writing, though. Whereas studies of composing processes in the 1980s were somewhat naturally bounded by the writing space and text the singular writer produced in isolation, contemporary literate practices are often networked and interactive, involving identifiable groups of people as well as innumerable, unidentified “publics.” For example, in the Instant Messaging study, we were interested in examining and identifying the forms of the writing being produced in IM, which at the time of data collection was a relatively new phenomenon, largely used by young people. In order to identify the features of the writing as it existed in situ, an important feature of that study was the collection of naturally-occurring IM conversations. In our study, to eliminate the possibility of participants composing IM transcripts with a university language researcher audience in mind, we asked participants to provide transcripts that pre-dated our invitation to participate in the study.
Participants in the IM study gave consent, captured and emailed transcripts of their IM conversations to our research team, and we stripped the transcripts of proper names, identifying speakers as “male,” “female,” male2,” or “female2” in order to keep track of speakers (see Figure 3).

Figure 3. Instant messaging transcript.
In doing so, we were in compliance with our Institutional Review Board (IRB), that required signed consent forms and confidentiality for participants through the use of pseudonyms. This meant, for example, that Male 9 in Figure 2 gave his consent and then captured and emailed the transcript of this conversation with Male 10 to our research team. At some point well into the data analysis, we realized that while our study had IRB approval and we had obtained consent from participants who shared transcripts with us, our study involved participants we had not anticipated – not just those whose consent we had (for example, Male 9) but also people (Male 10) with whom we did not have any contact. Our specific decision to focus on retroactive discussions in order to capture naturally-occurring data (a key feature of our research design) resulted in the inclusion of what I’ve come think of as “unanticipated participants” – people situated within the communicative context who are not our primary research focus but who are involved unintentionally or unexpectedly through their networked connection to the identified, consenting participant.
Likewise, in the Facebook study, individuals gave consent for the use of their think-aloud screencasts as they engaged in literate practices in Facebook. Consenting participants allowed us access to more than just their process of composing when they provided us with the screencasts, though—the screencasts showed the participant’s Facebook profile and wall, including the images and names of the friends with whom they were connected—people with whom, again, we the researchers had no contact. One individual’s Facebook Wall is networked with many other people’s names, images, writing, and other identifying features. These unanticipated others had not provided consent or been informed by our research team that their FB writing was being captured for our study. The number of unanticipated others in a study such as one focused on social networking can be quite significant: In just 10 seconds of one FB participant’s screencast, over 65 unique unanticipated participants are identifiable by name (with about a fourth of those identifiable by an accompanying image of them).
Participant selection in qualitative research has often been treated as a fairly straightforward process of identifying human participants whose experience or behavior can provide answers to the research question. Catherine Marshall and Gretchen Rossman suggest that “Decisions about sampling people and events are made concurrently with decisions about the specific data collection methods to be used and should be thought through in advance” (105). The IM and FB research teams both made decisions about sample populations concurrently with decisions about the specific data collection methods, in particular in terms of how both the data collection and the participant sample would provide insight into the research questions. The entwined, amorphous nature of the internetworked environments in which the participants wrote, and the precision with which the data collection method captured in detail all those who participated in those environments, challenged our ability on both teams to think through the participant population in advance.
Increasingly, it is impossible to understand literacy as an isolated activity; as the examples above reveal quite strikingly, literacy is at even the most basic level very much a social practice. Individual writers’ processes and texts are more and more entwined with other people’s writing. Indeed, as writers increasingly engage in literacy in interactive digital spaces that bring together complex and vast networks of other participants, unanticipated participants are increasingly present, and researchers are faced with equally complicated decisions about sampling, participant selection, and consent. Studies of composing processes easily might have been bounded at one time by a focus on a single individual writing with a pen and paper, but contemporary forms of writing are not so easily bounded, as writers engaging in virtually every form of writing (from completing forms to communicating in 140 characters with a real identifiable audience to writing essayist compositions) are entangled in sometimes vast networks of other writers, other texts, and other composing processes. Studies of contemporary literacy processes, thus, push on the bounds of what we mean by “research participant” and the limits of consent in our research. Similarly, as I discuss in the following section, these challenges of consent and peripheral boundaries arise when researchers capture composing processes and discover they have inadvertently captured peripheral data.
Another significant ethical issue facing researchers studying digital literacy composing involves the ways digital data capture practices complicate issues of privacy and consent. Parallel to the ways digital research can unintentionally involve unanticipated participants, digital research can likewise unintentionally involve peripheral data—data that is captured within the larger context of the composing environment but that is peripheral to the data the researcher has set out to collect. Participants may give their consent for us to observe and record their individual literacy activities, but in a networked, digital world, those activities rarely stand alone as individual, isolated pieces of text. Instead, literacy in a networked world is increasingly interactive and dependent on the participation of others in constructing the text. For researchers, this can complicate how data is collected (and in particular, how it is bounded).
Work on the Facebook research team made visible the nature of these complications, particularly in terms of what informed consent might involve in a digital age. Our eight participants’ signed consent forms informed them that we would be recording their processes using a screen capture program and that in future publications or presentations, we might include screen-captured images of their computer screens. During the data analysis phase of our research, I became interested in describing the idiosyncratic process of navigating the Facebook interface; participants seemed to have developed their own unique and slightly different ways of opening new links, moving around among Facebook’s different elements, and accessing the Facebook interface. I went through each of the participants’ screen capture videos to identify how they entered into the Facebook site: some had Facebook as their default page, some had a bookmark on their menu bar, and some typed “Facebook” into their URL bar. In the latter case, participants need not even enter the whole word “Facebook”: typing in the initial letters prompted Google to auto-complete the whole word. When they did that, the URL locator bar dropped down a history of recently visited and bookmarked sites that shared the initial letters that were entered. The image in Figure 4 is a screen capture of one moment (literally a split second) in which one participant, George, entered “f” in the URL locator bar that prompted Google to auto complete for “Facebook.”
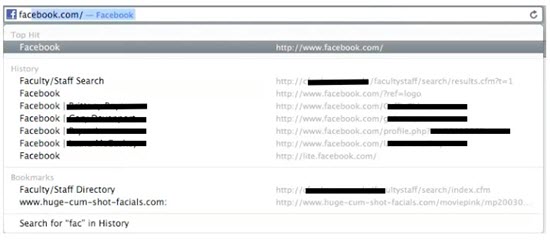
Figure 4. Facebook screen capture.
Pausing the screencast video to see how users enter the Facebook interface revealed some interesting things about participants’ uses of Facebook—for example, in the case of George, the fact that entering “f” into the URL bar prompted Google to auto-complete with “Facebook” suggests that Facebook is cached as this writer’s most frequently visited Web site with an “f” in it. Additionally, although in his recording sessions for our project George stayed on his Facebook Newsfeed page without navigating to any other pages, the links listed under “History” suggest that he had navigated to specific people’s Facebook pages (those names have been redacted in Figure 3). The screen capture images suggest, that is, that George’s data recording session for our project might have been shaped with his sense of the researcher over his shoulder. However, pausing the screen capture also revealed some things George might not have anticipated or guessed that same researcher would see. As Figure 3 shows, George’s bookmarks include “huge-cum-shot-facials.com.” Although the screen captures make readily apparent these details of George’s use of Google, George’s movement in the program was so quick that it’s easy to wonder if George was aware—in the literal split second it flashed on the screen—that the porn bookmark appeared in the screen capture he recorded for us. In our introduction of the study to participants, we had explained the screencast process; indeed, we’d had brief training sessions teaching participants how to use the screen capture and audio recording program. We had described potential uses for the data, although until we were immersed in the data analysis stage (long after the data had been collected and transcribed) we ourselves had not realized the peripheral data participants might be providing us through their screencast, including: programs on their desktops, filenames, web sites visited and bookmarked, user names, as well as the names, user ids, and images of others in their network.
The personally revealing data George shared was peripheral to our research questions, and while potentially embarrassing, it is a relatively innocuous example suggestive of the possibilities for more serious instances of participants revealing information they expect to be private. For example, if peripheral data revealed a participant’s involvement in criminal activity or suggested a participant at risk of harm to self or other, such information would have to be acted upon by the researcher (at the least, researchers experiencing unanticipated problems or adverse effects are required to report them to the IRB that initially approved the study).
The Belmont Report, which IRB committees use as a basis for human subjects research, requires researchers to enact respect for persons through informed consent, which, in part, describes for participants how their privacy will be protected. While our research team carefully planned for safeguards to do this, and our IRB approved our study, our research team learned that while screencasting captures composing processes in a rich way like no other data collection method, it also came with significant and unforeseen ethical complications. As Geisler and Slattery warn, “[b]ecause screen-capture software records all documents and interfaces as they appear on-screen, the data set may be replete with confidential information. The need to protect such information may mean that data must be carefully protected and any data to appear in a publication must be carefully screened and identifying information changed” (199). Even when researchers carefully protect information through the existing practices with which we’ve traditionally ensured confidentiality and anonymity of participants, though, the confidential information appearing in a screen-capture data set raises new and complicated ethical issues.
Kairos and Strategies for Studying Digital Literacy Composing Processes
James Paul Gee has described the network of forces involved in what he calls Discourse with a capital D: “distinctive ways of speaking/listening and often, too, writing/reading coupled with distinctive ways of acting, interacting, valuing, feeling, dressing, thinking, believing with other people and with various objects, tools, and technologies, so as to enact specific socially recognizable identities engaged in specific socially recognizable activities” (152). In this understanding, literacy is not the centerpiece of social activity but instead an activity often accompanied by ways of acting, interacting, valuing, feeling, dressing, thinking, believing. What is important about literacy is the ways it is used “so as to enact specific socially recognizable identities engaged in specific socially recognizable activities.” To account for literacy as a social practice of meaning making, we need accounts that capture these many ways of being in the world with written language, as well as accounts that capture what it is people actually do in the moment of composing the products of literate interaction.
Ellen Barton has argued that “[t]o an empirical researcher, the field of composition today seems dangerously near to losing whole types and areas of research questions, particularly questions of an empirical nature. Fewer and fewer studies, it seems, ask questions about how people think and write, about how people compose in real time, or about how groups of people write, traditionally topics that are investigated in empirical studies” (407). The kinds of research questions Barton suggests are ones that I wholeheartedly agree are necessary for understanding the ways people are composing and using literacy across their lives with contemporary technologies. Contemporary composing processes—involving new technological contexts, composing and design tools that situate the written word as one mode among many, and expanded and public networks of audiences—pose a special challenge as an object of study across the whole of the research process (from the kinds of research questions we pose, through the research design and data collection to the analysis and finalizing of a data-based argument). These challenges are likely to continue to push on existing research practices and require new strategies for research. I have suggested here some of the challenges I have experienced in researching digital literacy composing, but as with any research undertaking, it’s impossible to foresee and plan for every challenge.
Literacy researchers may navigate these challenges by developing a heightened sense of the kairotic decision-making Katrina Powell and I suggest researchers rely on particularly when navigating ethical waters. We describe kairos as “a contextually bound principle that determines appropriate and right truth only through a consideration of the rhetorical situation [because] appropriateness can be determined only within the moment, only within the context of the research process, only with the involvement of participants and the research site” (Powell and Takayoshi 415). A key component of kairos is being prepared to engage in moments of dissensus. Although researchers cannot be prepared for every specific challenge arising from the unique circumstance of their research project, they can prepare for the possibility of kairotic decision making by being always watchful for moments of dissensus and vigilant about the ethical challenges that can arise at any stage in the process.
Be watchful for moments of dissensus. When facing a methodological challenge (of the kind I describe in this article, for example), a researcher might immediately search for a solution so she can quickly move on. But I believe the moments of dissensus are worth pausing over, probing, and examining. Exploring the implications of the conflict for what can be known, what can be said, and what can be used in answering the research question is ethically imperative and empirically responsible. By recognizing that there are likely to be moments of dissensus and by being watchful for those moments, researchers can be prepared to probe those moments and make them into productive moments of learning and deeper understanding. Likewise, researchers might be prepared for negotiating instances of dissensus “in the moment.” Especially when researching digital literacy composing, researchers are likely to be challenged to make decisions unique to the research context. With few studies of digital literacy composing as models and little methodological theory to guide them, researchers might adopt an explicitly recursive approach to research design, recognizing that as one encounters challenges, the researcher may need to revise her research design or the conduct of the research.
Reflective methodological narratives from literacy researchers provide one significant pathway for being prepared to navigate methodological and ethical challenges in the conduct of research on composing processes. I believe we need more of these narratives of the decision making process by researchers in the field. Reflecting on his experiences as an empirical researcher, Jeffrey Grabill has written, “As a less-experienced researcher, I used to worry that my own practices did not measure up to the idealized practices articulated in methodological literatures. This is a useful worry. But I also think it is important to provide more nuanced accounts of research practice so that we can become vigilant but not anxious researchers” (218). I, too, share Grabill’s belief that although the challenges of methodology are often left out of the orderly narratives of research studies, researchers can learn from the experiences of researchers before us who have negotiated and built responses to those challenges. Even in research articles that focus on a student’s results rather than researcher’s narratives of practice, however, we can pay “greater attention to accounts of research method, both for the reader’s sake and the writer’s” (Smagorinsky, “The Method” 394). Especially with respect to newly developing literate practices, greater attention to research methods and practices is a significant first step in developing methods which ethically and accurately capture these new practices.
Be vigilant about the ethical challenges. Researchers of contemporary composing processes need to be prepared for ethical issues to arise at any and every stage in the process—ethics are not just a matter of human subjects’ relationships but a matter of consequence across the entire research process. Heidi McKee and James Porter see research ethics not as something static addressed at the beginning of the research process or left only to the oversight of those outside the process (like IRB boards) but as “a continuous process of inquiry, interaction, and critique throughout an entire research study, one involving regular checking and critique; interaction and communication with various communities; and heuristic, self-introspective challenging of one’s assumptions, theories, designs, and practices” (739). This awareness of one’s assumptions, theories, designs, and practices as they relate to research ethics connects to a larger call for self-reflexivity and an awareness of how one’s interpretive, knowledge making, and analytic processes interact with and shape the research project as a whole. It is the responsibility of researchers to enact ethical practices as they arise in the study regardless of IRB approval. As Marshall and Rossman note, “Ethical practice is ongoing; obtaining a signature on an informed consent form is merely one observable indicator of the researcher’s sensitivity” (48). Realizing that ethical concerns involving the varying expectations of privacy by participants and peripheral participants are very context-dependent, there is no algorithm that addresses how participants and peripheral participants might be selected for digital literacy composing research. Instead, the complexity of these ethical issues underscores the importance of thinking carefully about ethical matters at every stage in digital literacy composing research design. Ethical matters are not merely a matter of how we work with human participants or how we represent them in our final manuscripts. With digital literacy composing research (especially research located closely to the moment of composing as suggested in Figure 1), researchers are faced with ethical decision making at every stage of the research design.
For example, the complications that arise from the range of peripheral data present in screencasts and screen captures might require researchers to enact specific practices to inform participants about the potential peripheral information captured in screencast and screen capture data. In addition to describing for participants the potential forms the data might take (in terms of presentations and publications), we might describe for participants the processes by which data might be analyzed prior to the final representational form, showing them how screen recording technologies might be used. New research practices might also involve being explicit in our consent forms about the analytic processes unique to video screen capture (including the researcher’s ability to view screens and actions repeatedly, to pause and capture fleeting moments, to encounter information about participants in the environment who are peripheral to the writing process, and to collect data about others with whom the participant interacts).
In a digital world, literacy is fully and meaningfully present across people’s lifeworlds. Composition studies has recognized the wide-ranging functions of writing, the meanings these acts of written communication have for writers, and the importance for writing researchers and teachers of understanding those functions and values for literacy in people’s lives as learners, workers, and citizens. Increasingly, we as a field have come to understand that much of this writing is being composed in digital, networked, and interactive writing spaces. Arguing that digital literacy composing processes present unique challenges for researchers investigating digital literacy composing, in this article, I have offered guidance for handling some of those challenges. This of course is just an opening move; as researchers immerse themselves in the study of digital literacy composing processes and practices as they are mediated in contemporary writing spaces, our disciplinary understanding of what it means to develop reliable, ethical research practices will certainly only expand.